 這是經典的概念題。要寫出能動的程式很簡單, 要去解釋背後的記憶體管理運用原則, 還是需要一點時間內化。而且不知道為什麼, 一般的軟體工程師跟架構師來說這兩個詞, 那個講起來那個味道就是不太一樣, 有時候面談別人時, 還會覺得有些求職者有獨到的見解。
這是經典的概念題。要寫出能動的程式很簡單, 要去解釋背後的記憶體管理運用原則, 還是需要一點時間內化。而且不知道為什麼, 一般的軟體工程師跟架構師來說這兩個詞, 那個講起來那個味道就是不太一樣, 有時候面談別人時, 還會覺得有些求職者有獨到的見解。簡單來說, 從記憶體配置的角度, 用一個二分法
- stack 用於靜態記憶體配置, 大陸翻譯為棧, 棧, 棧 (why ?)
- heap 用於動態記憶體配置, 大陸翻譯為堆
這張 All-in-one 的圖是我目前最喜歡的圖像解釋, 來源是 Six important .NET concepts: Stack, heap, value types, reference types, boxing, and unboxing :
首先記得這個範例, 圖片是由上而下逐行介紹,
public void Method1()
{
int i = 4; //Line1
int y = 2; //Line2
Class1 cls1 = new Class1(); //Line3
}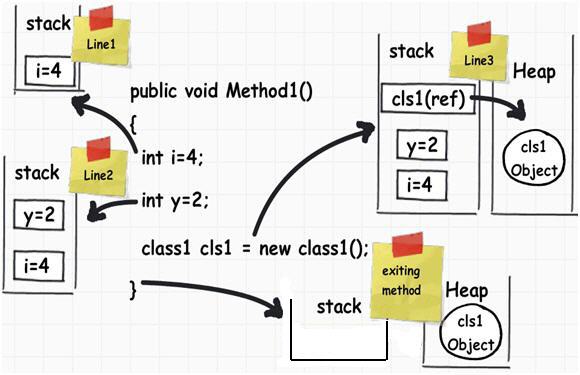
總結是 :
- value type 的變數, 包括指標變數會放在 stack
- reference type 的變數 (如 string, object) 本身也會放 stack, 然而他的值 (value) 則是放 heap
- boxing 就是 value types to reference types 的過程, 所以 value 會被放到 heap 中, 而產生一個 object 變數來指向這個 value, 變數指標則是在 stack
- unboxing 是 reference types to value types 的過程, 所以原本 object 所指向的值 (heap 中) 會被複製到 stack 中並賦予明確 value type 型別
深入 Stack
現在回到最原點, 我們略懂 stack 與 heap 的區別了, 但還是沒有一個「感覺」對不對 ? 因為我們不懂 why。我個人建議有空可以 K 一下這篇 stack (英文, 請慎入) 掌握 stack 的記憶體運作原則, heap 的運作待補。筆記如下 :- 記憶體 - 資料存放的角度
- 記憶體 - 程式運行的角度

記憶體 - 資料存放的角度
stack 的操作特色是 LIFO (last in, first out), 所以依序呼叫 push(), push(), pop() 後, 是第二個 push 進去的資料會被 pop 出來, 而不是第一個 (相反的叫 FIFO, 一般的 queue 就是這個行為)。push: addi $sp, $sp, -4 # Decrement stack pointer by 4
sw $r3, 0($sp) # Save $r3 to stack
pop: lw $r3, 0($sp) # Copy from stack to $r3
addi $sp, $sp, 4 # Increment stack pointer by 4
push() 的記憶體核心操作其實是在記憶體中的堆疊位址 (Stack Pointer) 先往低位址移動 (0x00100000 → 0x000ffffc), 然後在新位址 (0x000ffffc) 存入資料; 相反地, pop() 則是先把目前位址 (0x000ffffc) 的值 copy 出來 (通常我們會想取得 pop 出來的值的吧, 丟掉可惜了), 然後記憶體中的堆疊位址再回到上一個 SP (0x000ffffc → 0x00100000)。


記憶體 - 程式運行的角度
讓我們從一段 C 語言程式碼反窺 stack 如何支持程式運行 :
#include <iostream>
using namespace std;
int main( int argc, char *argv[], char *envp[] )
{
int i = 1;
foo(i, argc);
cout << "Hello World !" << "\n";
}


原來一段程式碼能更運作, 並非想像中這麼單純, 但讀懂之後就慢慢開啟了計算機的奧秘。 overall 來看, 是進入 main() → 呼叫 foo() → 結束 main() 的過程, 但從細節來說, 是這樣的 :
- 粗略版 : 進入 main() → 呼叫 foo() → 結束 main()
- 粗略版 : 進入 main() → 呼叫 foo() → 結束 foo() → 結束 main()
- 細微版 : 進入 main() → 儲存 main 區域變數與呼叫參數 → 呼叫 foo() → 儲存 foo 區域變數與呼叫參數 → 結束 foo() → 結束 main()
- 精緻版 : 進入 main() → 儲存 main 區域變數與呼叫參數 → 配置foo 回傳結果位址 → 呼叫 foo() → 儲存 foo 區域變數與呼叫參數 → 結束 foo() → 回存 foo 回傳結果→ 接續執行 main() → 結束 main()
如此, 每個 stack 內的 pointer 指向很明確的目標, 一路往上堆疊深入運行, 再一路返回到呼叫原點, 是不是開始覺得 LIFO 這個設計概念設計的偉大之處, 這就是 stack。提醒一下, 如上圖顯示, 可以看到 stack 的記憶體空間是有個極限的, 萬一堆太高堆太深堆到爆掉, 就會發生 System.StackOverflowException 的錯誤, 太多層的 loop 或 recursive 都很容易發生的。
好文!
ReplyDelete我可以幫你補充一點些
boxing unboxing 只會發生在實質型別 To 參考型別 or 參考型別 To 實質型別
如果兩者皆為參考型別就不會發生這樣的事情
string A = "A";
Object B = A ;
而外補充 .Tostring( ) 並不在規範內
而Boxing 是隱含轉型,unboxing 必須明確轉型
如果可以當然避免 拆裝箱的效能損耗
如果有機會使用泛型的型別參數,那麼就有機會可以免這個問題發生
感謝回饋
Delete(noted)
解說的清楚,第一次接觸這麼進階的程式架構!!
ReplyDelete稍微筆記, 我自己也會忘 XD
Delete